
Explainable Artificial Intelligence: Learnable Explanations for Neural Networks
Research Problem
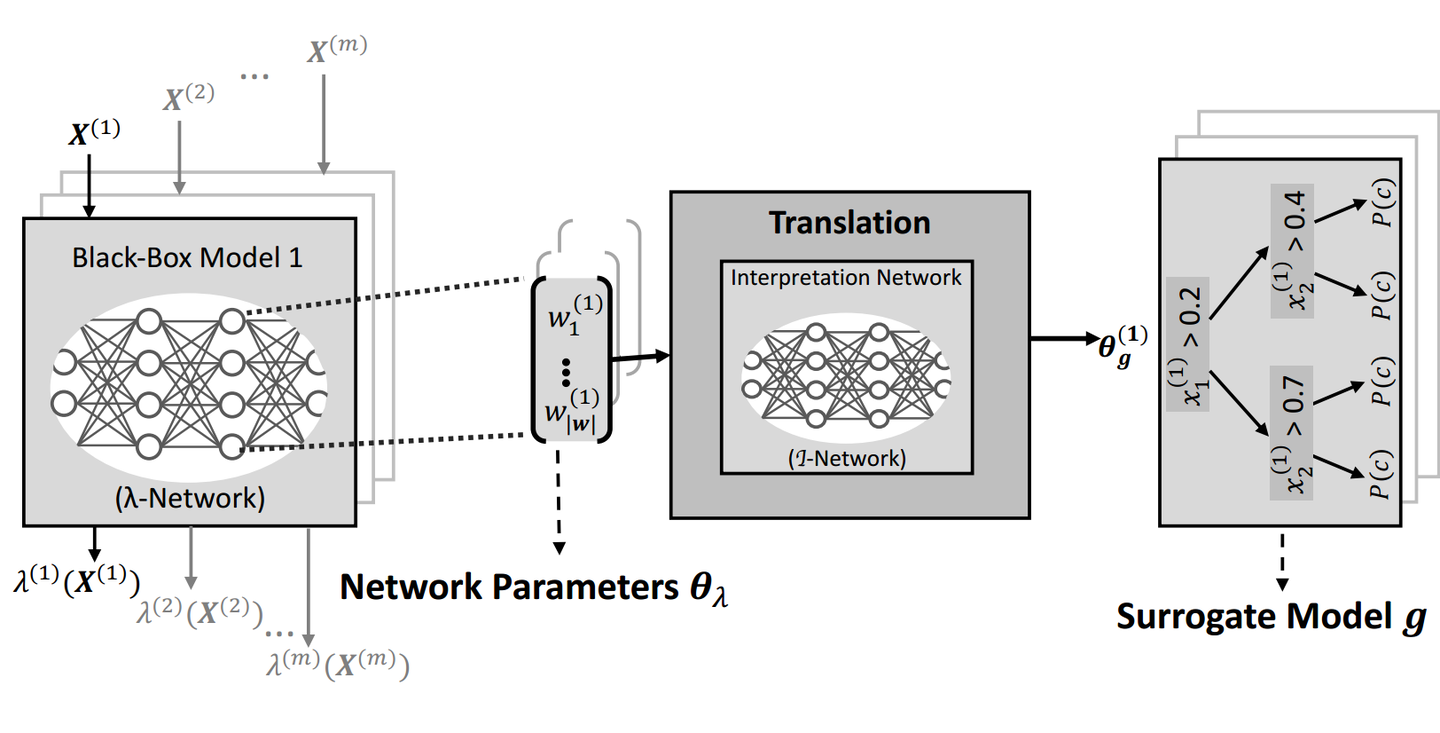
Understanding the function learned by a neural network is crucial in many domains, e.g. to detect a model's adaption to concept drift in online learning. Existing global surrogate model approaches generate explanations by maximizing the fidelity between the neural network and a surrogate model on a sample-basis, which can be very time-consuming. Therefore, these approaches are not applicable in scenarios where timely or frequent explanations are required.
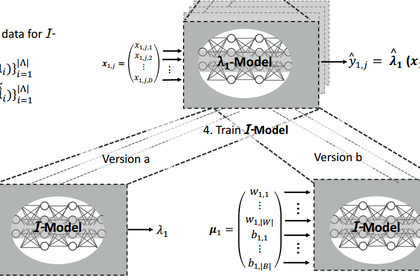
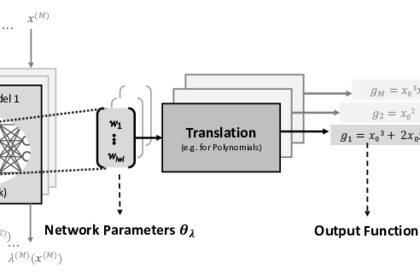
In this work, we introduce a real-time approach for generating a symbolic representation of the function learned by a neural network. Our idea is to generate explanations via another neural network (called Interpretation Network), which maps network parameters to a symbolic representation of the network function. This way, the complete information about the network function can be utilized for generating explanations, without access to training data and without resorting to sampling.
We show that the training of an Interpretation Network for a family of functions (e.g. a mathematical function or decision tree) can be performed up-front, and subsequent generation of an explanation only requires to query the Interpretation Network once, which is computationally very efficient and does not require training data. To the best of our knowledge, this is the first approach that attempts to learn the mapping from neural networks to symbolic representations.
Contact

Sascha Marton
Institute for Enterprise Systems
L15, 1–6 – Room 416
68161 Mannheim

Prof. Dr. Christian Bartelt
Institut für Enterprise Systems
L 15, 1–6 – Room 417
68161 Mannheim