
Self-Learning Governance of Multi-Agent Systems
Research Problem
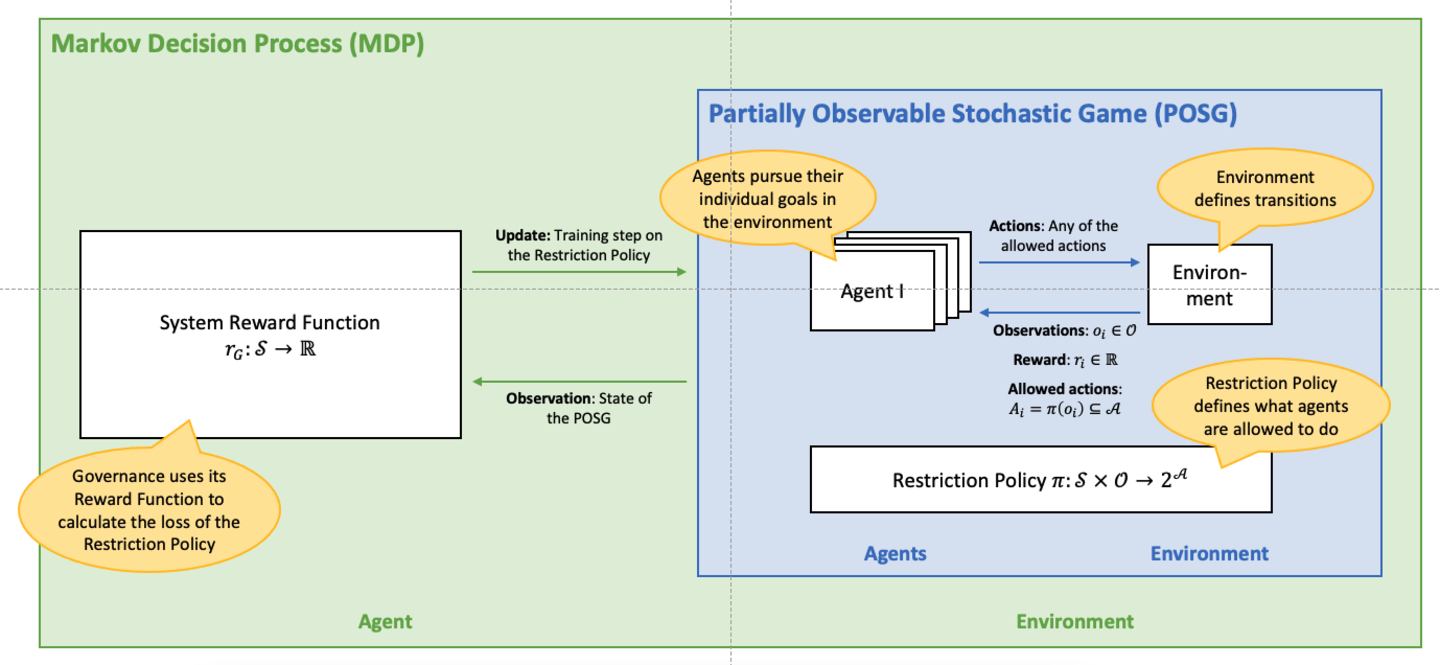
Multi-Agent Systems (MAS) are a widely used model to describe and analyze systems of autonomous decision-makers, or agents, who interact on an environment. In these systems, the result of the interaction depends simultaneously on all agents’ actions, leading to strategic behavior and potential conflicts. There are many existing approaches to enable agents to learn optimally in this type of environment, which is formally modeled as a Stochastic Game or Markov Game—a multi-agent version of a Markov Decision Process (MDP) and, at the same time, a stateful version of the game-theoretic concept of a Matrix Game. Most of these approaches focus on the agents and their strategies; the most successful of them is Multi-Agent Reinforcement Learning (MARL).
However, since a Stochastic Game is inherently non-stationary, the well-known convergence criteria for classical Reinforcement Learning algorithms on MDPs no longer hold. Recent algorithms for MARL can be shown to converge to certain equilibria for sub-classes of Stochastic Games like zero-sum games and Markov Team Games, but the problem is still open for general-sum Markov Games.
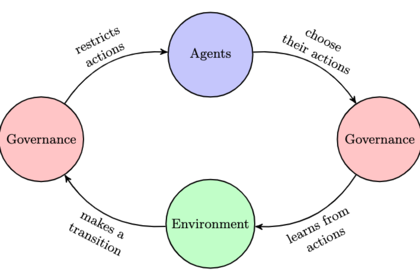
Our work introduces and explores a novel approach, Governed Multi-Agent Systems (GMAS), based on a concept from Normative Multi-Agent Systems, the Electronic Institution (EI). In this model, there is another system component (an institution, or Governance, as we call it) which can restrict the agents’ action spaces in a MAS at runtime. Using Deep Reinforcement Learning as the rule-setting and rule-updating method, we can show that the Governance is able to purposefully restrict the set of allowed action in order to achieve a given system objective, while preserving the agents’ autonomy.
Contact

Dr. Michael Oesterle
Institute for Enterprise Systems
L 15, 1–6
L15, 1–6 – Room 417
68161 Mannheim

Prof. Dr. Christian Bartelt
Institut für Enterprise Systems
L 15, 1–6 – Room 417
68161 Mannheim