Paper on Large-Scale Dataset Collection from Twitter accepted
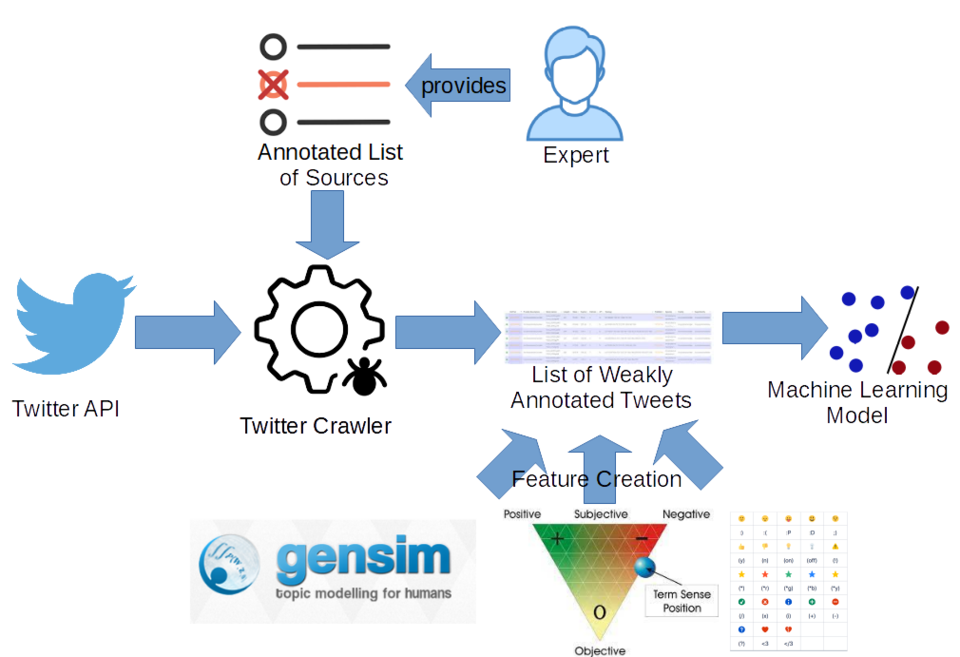
Tweet classification is a rather straight forward machine learning task, but usually requires a large-scale dataset for training. While labels for tasks such as sentiment analysis can be more easily acquired using crowdsourcing, labeling tweets for classification into fake and real news is a much more complex endeavour, since it often requires more in-depth examinations of the subject matter.
In this paper, we discuss an alternative approach: instead of manually labeling comparatively small datasets with exact labels, we propose an approach for creating large-scale datasets with noisy labels. We show that by training on a large scale noisy dataset acquired with minimal human intervention, we can achieve equally good results as when using scarce exact training data. Moreover, we demonstrate that by combining a large dataset with noisy labels and a small dataset with exact labels, it is possible to achieve even better results.
The work was jointly done by Stefan Helmstetter, who was a Master's student at the DWS group, and Heiko Paulheim. It is now published in the open access journal Future Internet in a special issue on “Digital and Social Media in the Disinformation Age”.