Improving Stability during Upsampling--on the Importance of Spatial Context
Accepted at ECCV 2024
Useful Links:
- Paper
- Slides for better understanding
Poster

Abstract
Pixel-wise predictions are required in a wide variety of tasks such as image restoration, image segmentation, or disparity estimation. Common models involve several stages of data resampling, in which the resolution of feature maps is first reduced to aggregate information and then increased to generate a high-resolution output. Previous works have shown that resampling operations are subject to artifacts such as aliasing. During downsampling, aliases have been shown to compromise the prediction stability of image classifiers. During upsampling, they have been leveraged to detect generated content.
Yet, the effect of aliases during upsampling has not yet been discussed w.r.t. the stability and robustness of pixel-wise predictions. While falling under the same term (aliasing), the challenges for correct upsampling in neural networks differ significantly from those during downsampling: when downsampling, some high frequencies can not be correctly represented and have to be removed to avoid aliases. However, when upsampling for pixel-wise predictions, we actually require the model to restore such high frequencies that can not be encoded in lower resolutions. The application of findings from signal processing is therefore a necessary but not a sufficient condition to achieve the desirable output. In contrast, we find that the availability of large spatial context during upsampling allows to provide stable, high-quality pixel-wise predictions, even when fully learning all filter weights.
Proposed Hypothesis
Hypothesis 1 (H1):
Large Context Transposed Convolutions (LCTC) i.e. Large kernels in transposed convolution operations provide more context and reduce spectral artifacts and can therefore be leveraged by the network to facilitate better and more robust pixel-wise predictions.
Hypothesis 2 (H2, Null Hypothesis):
To leverage prediction context and reduce spectral artifacts, it is crucial to increase the size of the transposed convolution kernels (upsample using large filters). Increasing the size of normal (i.e. non-upsampling) decoder convolutions does not have this effect.
Visualizing Spectral Artifacts in the Frequency Spectra

Image restoration example using NAFNet variants on the GoPro dataset. Upsampling techniques like Pixel Shuffle first row) and transposed convolution using small learnable filters (2×2 or 3×3) (second row) are used by most prior art. Both lead to spectral artifacts for which the model needs to compensate. The clean (in-domain) restored images look appealing – while adversaries (here 5-step PGD attack) can leverage aliases such that artifacts become easily visible. When observed in the frequency domain, they manifest as repeating peaks all over the spectra. Based on sampling theoretic considerations, we propose Large Context Transposed Convolutions (7×7 or larger) (bottom row). They significantly increase the model’s stability during upsampling, observable in the restored image under attack and the frequency spectrum.
What causes Spectral Artifacts?

Alleviating Spectral Artifacts due to upsampling

An image from GoPro dataset downsampled with 3×3 MaxPooling and then upsampled using various upsampling techniques. The resulting artifacts are compared on zoomed-in red box regions for better visibility. Bilinear interpolation causes over-smoothing. Bicubic interpolation causes overestimation along image boundaries while Pixel Shuffle and Nearest Neighbor cause strong grid artifacts along with discoloration. Small kernel transposed convolutions cause grid artifacts, however, on increasing kernel size we start getting better upsampling.
Method
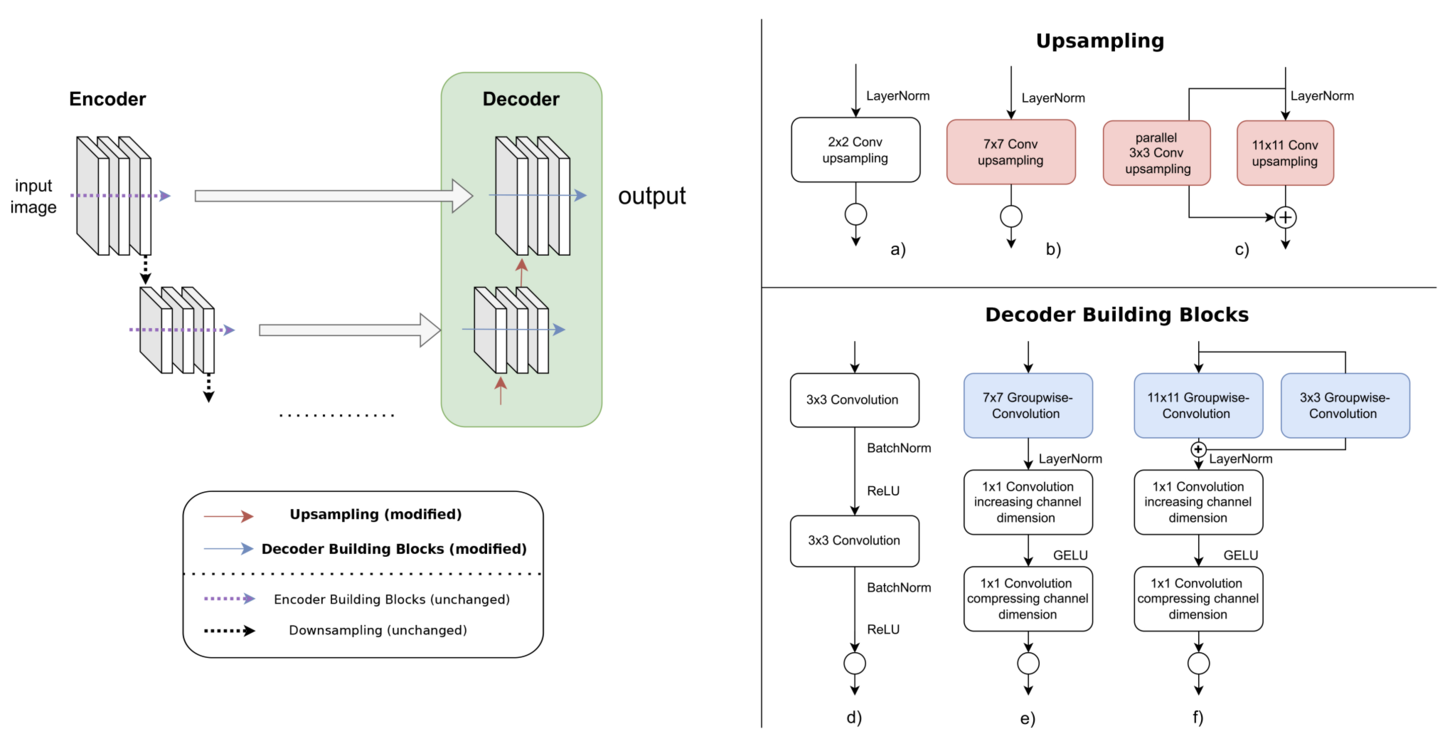
Abstract representation of an encoder-decoder architecture. While for different tasks, the implementation of the model encoder varies (including transformer-based encoders), our study focuses on the model decoder (in green). The backbone for the decoder is commonly a ResNet-like structure for feature extraction, additionally we also used a ConvNeXt-like structure. We investigate variants of different upsampling operations (the operations along the red arrows in the decoder) for fixed decoder blocks. We consider, as a probe for H1, the baseline transposed deconvolution (a) in the top right), and for LCTC an increased convolution kernel size (b) in the top right), and an increased convolution kernel with a second path using a small convolution kernel (c) in the top right). To test whether the plain increase in parameters is responsible for improved results (zero hypotheses, H2), we also ablate on the increase of convolution kernel size in the decoder block (operations along the blue arrows in the green block), as shown on the bottom right. We consider the common ResNet-like decoder building block structure (in d)) and two ConvNext-like structured backbones for the decoder building block in e) and f), where f) has an additional small convolution applied in parallel, analog to c).
Results

Acknowledgements
Margret Keuper acknowledges funding by the DFG Research Unit 5336 – Learning to Sense.
The OMNI cluster of University of Siegen was used for some of the initial computations.
Citation
As Normal Text:
Agnihotri, S., Grabinski, J., & Keuper, M. (2023). Improving Stability during Upsampling--on the Importance of Spatial Context. arXiv preprint arXiv:2311.17524.
BibTeX:
@misc{agnihotri2024improvingfeaturestabilityupsampling,
title={Improving Feature Stability during Upsampling -- Spectral Artifacts and the Importance of Spatial Context},
author={Shashank Agnihotri and Julia Grabinski and Margret Keuper},
year={2024},
eprint={2311.17524},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2311.17524},
}