Workshop on Reliability of Vision and Multi-Modal Models in the Real World
NeurIPS 2025 Workshop V3M
Keynote Speakers






We are honored to present an outstanding panel of distinguished speakers, each leading expert in their respective f ields, whose diverse expertise will significantly enrich the workshop’s discourse. Spanning critical areas such as trustworthy AI, security, privacy, and generalization in the wild (Prof. Dr. Mario Fritz, Prof. Dr. Dawn Song, and Irena Gao), advancements in trustworthy and reliable applications of machine learning in neuroscience and healthcare applications and automated machine learning (Prof. Dr. Sanmi Koyejo, and Dr. Minseom Kim), and discussion on broader aspects on the reliability of Machine Learning and AI (Bart Van Der Sloot), our speakers bring invaluable perspectives to the discussion. Their collective insights align with the workshop’s focus on advancing the reliability and generalization of vision models in real-world contexts, promising a robust and multifaceted exploration of these pressing challenges. All our speakers have confirmed their attendance.
Description
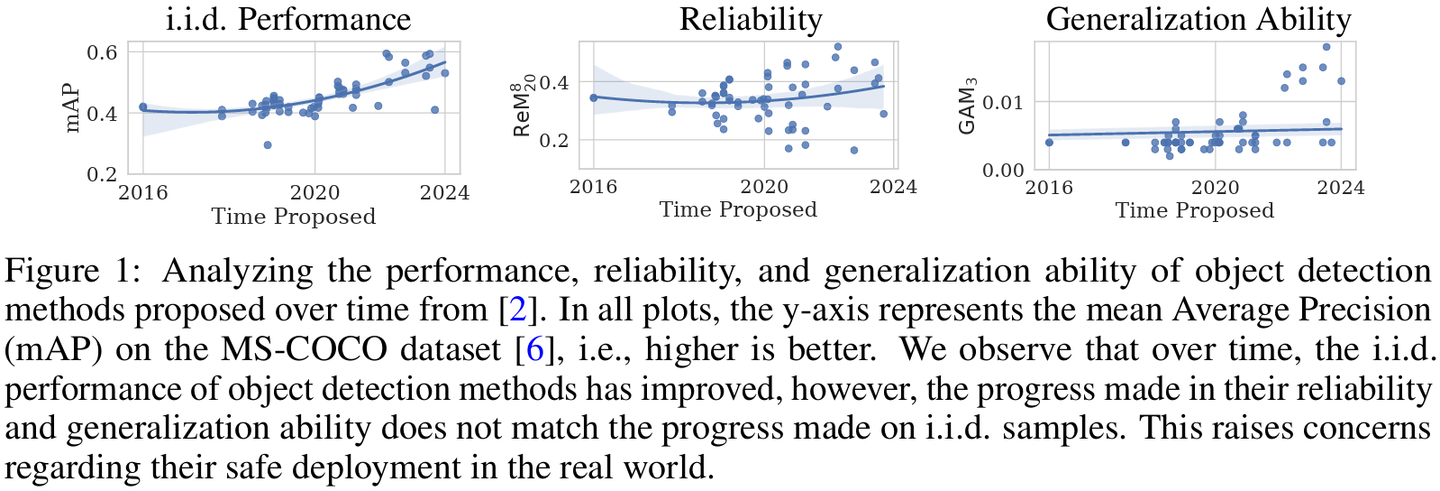
Machine learning models face increasing challenges in reliability and generalization when applied to real-world scenarios. We observe in Figure 1,that for the vision task of Object Detection, while the i.i.d. performance has improved by the methods proposed over the years, their reliability and generalization ability are still stagnant. These methods include multi-modal models like GLIP [5] and MM-Grounding-Dino [7]. This has occurred due to community’s focus on improving i.i.d. performance, disregarding the reliability and generalization ability of their proposed methods. Now, these models are not deployable in the real world. Thus, this workshop focuses on advancing theoretical and practical approaches to ensure vision and multi-modal models can perform under distributional shifts and noisy environments, and by extension in the real world. Topics include robustness analysis, certified defenses, and evaluations under real-world conditions. We invite discussions on novel learning paradigms, practical applications, and benchmarking efforts essential for building resilient models.
Topics Covered
Recent research has highlighted the vulnerabilities of Vision Language Models (VLMs) and other foundation and multi-modal models [3, 4], primarily within the context of classification tasks [1]. However, there is significant potential to extend these findings to real-world applications beyond image classification. We welcome contributions across the following themes:
- Robustness and Failure Modes in Real-World Vision Tasks
Methods that improve and evaluate the reliability of multi-modal models on tasks like semantic segmentation, object detection, and optical flow, especially under distribution shifts, adversarial attacks, or sensor noise. - Evaluation Frameworks, Metrics, and Certification
New metrics and certification tools for robustness, particularly for downstream tasks where existing benchmarks fall short, and where interpretability and safety are critical (e.g., medical, autonomous driving). - Architectural and Deployment Considerations
How do architectural choices (e.g., pruning, sparsity) and deployment on edge devices affect model reliability? We welcome research on scalable and energy-efficient yet dependable multi-modal model design. - Attacks, Red-Teaming, and Hallucination Detection
Submissions exploring security vulnerabilities in multi-modal and vision foundation models—including backdoor attacks, jailbreaking, and hallucination detection—are encouraged, along with red-teaming methods. - Real-World Dataset Challenges and Signal Processing Effects
Works addressing challenges from long-tailed distributions, ISP artifacts, or modality-specific distortions. Special interest lies in datasets and evaluations that reflect true deployment conditions. - Negative Results
Many defense methods have been proposed to increase the reliability and generalization abilities of classification models; however, they might not directly translate to multi-modal models beyond classification. We welcome submissions that show the failure of such methods to promote discussions on possible fixes.
Call For Papers
The submissions for FULL PAPER and EXTENDED ABSTRACTS will happen using the following OpenReview submission portal.
The submission portal opens on 15th July, 2025.
Despite the remarkable progress of Vision-Language Models (VLMs) and other foundation models, their reliability and generalization in real-world scenarios remain open challenges—especially for tasks beyond image classification. This workshop aims to bring together researchers and practitioners to explore the robustness, safety, and deployment-readiness of multi-modal systems under real-world conditions.
We welcome submissions on topics including, but not limited to:
- Robustness and Failure Modes in structured tasks such as segmentation, detection, and optical flow
- Evaluation Frameworks and Certified Robustness for vision and multi-modal models
- Architectural Design Choices and deployment on edge or resource-constrained devices
- Security and Safety: adversarial attacks, backdoors, red-teaming, and hallucination detection
- Real-World Dataset and ISP Challenges, including long-tailed data, sensor-specific effects, and deployment-time noise
- Negative Results: failed methods and lessons learned when classification-based defenses fail to generalize
Submission Types
We offer two types of submissions:
- Extended Abstract
- Up to 4 pages (excluding references)
- Non-archival; ideal for early-stage ideas or ongoing work
- Accepted papers will be presented as posters or short talks
- Full Paper
- Up to 9 pages (excluding references)
- Selected papers will be published in the NeurIPS 2025 Workshop Proceedings (PMLR)
- Presented as talks or spotlight posters
Formatting Guidelines
- All submissions must follow the official NeurIPS paper template
- Submissions must be double-blind and adhere to ethical guidelines
- Supplementary materials are optional and do not count toward the page limit
Important Dates (AoE)
- Submission Deadline: August 22, 2025
- Review Period & Oral Decisions: August 23 – September 17, 2025
- Notification of Acceptance: September 22, 2025
- Camera-Ready Deadline: October 15, 2025
- Workshop Date: December 6 or 7, 2025
Workshop Schedule
We plan to hold 6 invited talks from senior researchers, oral sessions for 3 papers.
We will split all the accepted posters equally in the 2 poster sessions, such that each poster gets ample visibility.
Total Duration: 9 hours
Each invited/
All times are local (TBD based on NeurIPS timezone).
- 09:00 – 09:15 — Opening Remarks and Best Paper Award Announcement
09:15 – 09:45 — Invited Talk 1 (20+10 min)
09:45 – 10:15 — Invited Talk 2 (20+10 min)
10:15 – 10:45 — Invited Talk 3 (20+10 min)
- 10:45 – 11:00 — ☕ Coffee Break 1
- 11:00 – 11:30 — Oral Presentation 1 (20+10 min)
11:30 – 12:00 — Oral Presentation 2 (20+10 min)
- 12:00 – 13:15 — Poster Session 1 and Informal Discussions
- 13:15 – 14:00 — Lunch Break
- 14:00 – 14:30 — Invited Talk 4 (20+10 min)
14:30 – 15:00 — Invited Talk 5 (20+10 min)
15:00 – 15:30 — Invited Talk 6 (20+10 min)
- 15:30 – 15:45 — ☕ Coffee Break 2
- 15:45 – 16:15 — Panel Discussion: Reliability of Multi-Modal Models in Deployment
- 16:15 – 16:45 — Oral Presentation 3 (20+10 min)
16:45 – 18:00 — Poster Session 2
Organizers










Contact Us
In case of any queries please feel free to contact Shashank Agnihotri at shashank.agnihotri@uni-mannheim.de . To ensure that you get a reply, please include "[V3M]" in the subject of the email.
References
[1] ADDEPALLI, S. ; ASOKAN, A. R. ; SHARMA, L. ; BABU, R. V.: Leveraging vision-language models for improving domain generalization in image classification. In: Proceedings of the IEEE/
[2] AGNIHOTRI, S. ; SCHADER, D. ; JAKUBASSA, J. ; SHAREI, N. ; KRAL, S. ; KAÇAR, M. E. ; WEBER, R. ; KEUPER, M. : SemSegBench & DetecBench: Benchmarking Reliability and Generalization Beyond Classification. In: arXiv preprint arXiv:2505.18015 (2025)
[3] ANDRIUSHCHENKO, M. ; CROCE, F. ; FLAMMARION, N. : Jailbreaking Leading Safety-Aligned LLMswith Simple Adaptive Attacks. In: ICML 2024 Next Generation of AI Safety Workshop, 2024
[4] CHAO, P. ; DEBENEDETTI, E. ; ROBEY, A. ; ANDRIUSHCHENKO, M. ; CROCE, F. ; SEHWAG, V. ; DOBRIBAN, E. ; FLAMMARION, N. ; PAPPAS, G. J. ; TRAMÈR, F. u. a.: JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models. In: The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024
[5] LI, L. H. ; ZHANG, P. ; ZHANG, H. ; YANG, J. ; LI, C. ; ZHONG, Y. ; WANG, L. ; YUAN, L. ; ZHANG, L. ; HWANG, J.-N. u. a.: Grounded language-image pre-training. In: Proceedings of the IEEE/
[6] LIN, T.-Y. ; MAIRE, M. ; BELONGIE, S. ; HAYS, J. ; PERONA, P. ; RAMANAN, D. ; DOLLÁR, P. ; ZITNICK, C. L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V 13 Springer, 2014, S. 740–755
[7] ZHAO, X. ; CHEN, Y. ; XU, S. ; LI, X. ; WANG, X. ; LI, Y. ; HUANG, H. : An Open and Comprehensive Pipeline for Unified Object Grounding and Detection. In: arXiv preprint arXiv:2401.02361 (2024)
Related Workshops
- Workshop of Adversarial Machine Learning on Computer Vision: Art of Robustness (CVPR 2023)
- A Blessing in Disguise: The Prospects and Perils of Adversarial Machine Learning'' (ICML 2021)
- The Art of Robustness: Devil and Angel in Adversarial Machine Learning'' (CVPR 2022)
- 1st Workshop on Test-Time Adaptation: Model, Adapt Thyself!'' (CVPR 2024)
- VAL-FoMo: Emergent Visual Abilities and Limits of Foundation Models (ECCV 2024)
- Trustworthy Multimodal Learning with Foundation Models: Bridging the Gap between AI Research and Real World Applications (Symposium in BMVA 2024)
- R0-FoMo: Robustness of few-shot and zero-shot learning in large foundation models (NeurIPS 2023)
- Workshop on Adversarial Robustness In the Real World (AROW) (ICCV 2023)
- Workshop of Adversarial Machine Learning on Computer Vision (CVPR2020, CVPR2022, CVPR2023, and CVPR2024)
- ROAM: Robust, Out-of-Distribution And Multi-Modal models for Autonomous Driving (ECCV2024)
- Uncertainty Quantification for Computer Vision (ECCV 2022, ICCV2023, ECCV2024)
- Uncertainty and Robustness in Deep Learning (UDL) (ICML2019, ICML2020, ICML2021)
- ROAD workshop & challenge: Event detection for situation awareness in autonomous driving (ICCV2023, NeurIPS2023, ECCV2024)
- Workshop on Medical Computer Vision (CVPR2017, CVPR2021, CVPR2022, ECCV2022, CVPR2023)
- Workshop on Computer Vision for Automated Medical Diagnosis (CVAMD) (ICCV2023)
- Computer Vision in the Wild (ECCV2022, CVPR2023, CVPR2024)