
Example: Predicting the Fuel Consumption of Cars
This example shows how Linked Open Data can be used to improve the prediction of fuel consumption of cars. The corresponding RapidMiner workflow can be downloaded from myExperiment. The data was obtained form the UCI Auto MPG dataset, and the input CSV file for the process can be downloaded here.
The initial dataset contains the names of the cars, and 8 other attributes, including the label attribute MPG (miles per gallon). This example shows that using additional background knowledge from DBpedia for each of the cars, improves the prediction of fuel consumption of the cars.
Fig. 1 depicts the overall workflow in RapidMiner, which is divided in two sub-flows. In the first part we are trying to predict the fuel consumption using only the data from the initial dataset, while in the second sub-flow we are using additional knowledge extracted from DBpedia. To predict the fuel consumption we are using the M5 Rules operator, which is part of the Weka extension.

To link the cars dataset to DBpedia, we use the DBpedia Lookup linker. As a query class we use “Automobile, and we use the PrefixSearch API, as shown in Fig. 2. The output of the linker is multiplied, and passed to the feature generators. For feature generating we are using the Direct Types generator and the Specific Relation generator, which is used to extract the categories of the linked cars. Both of the generators are configured with the standard DBpedia Sparql Endpoint.
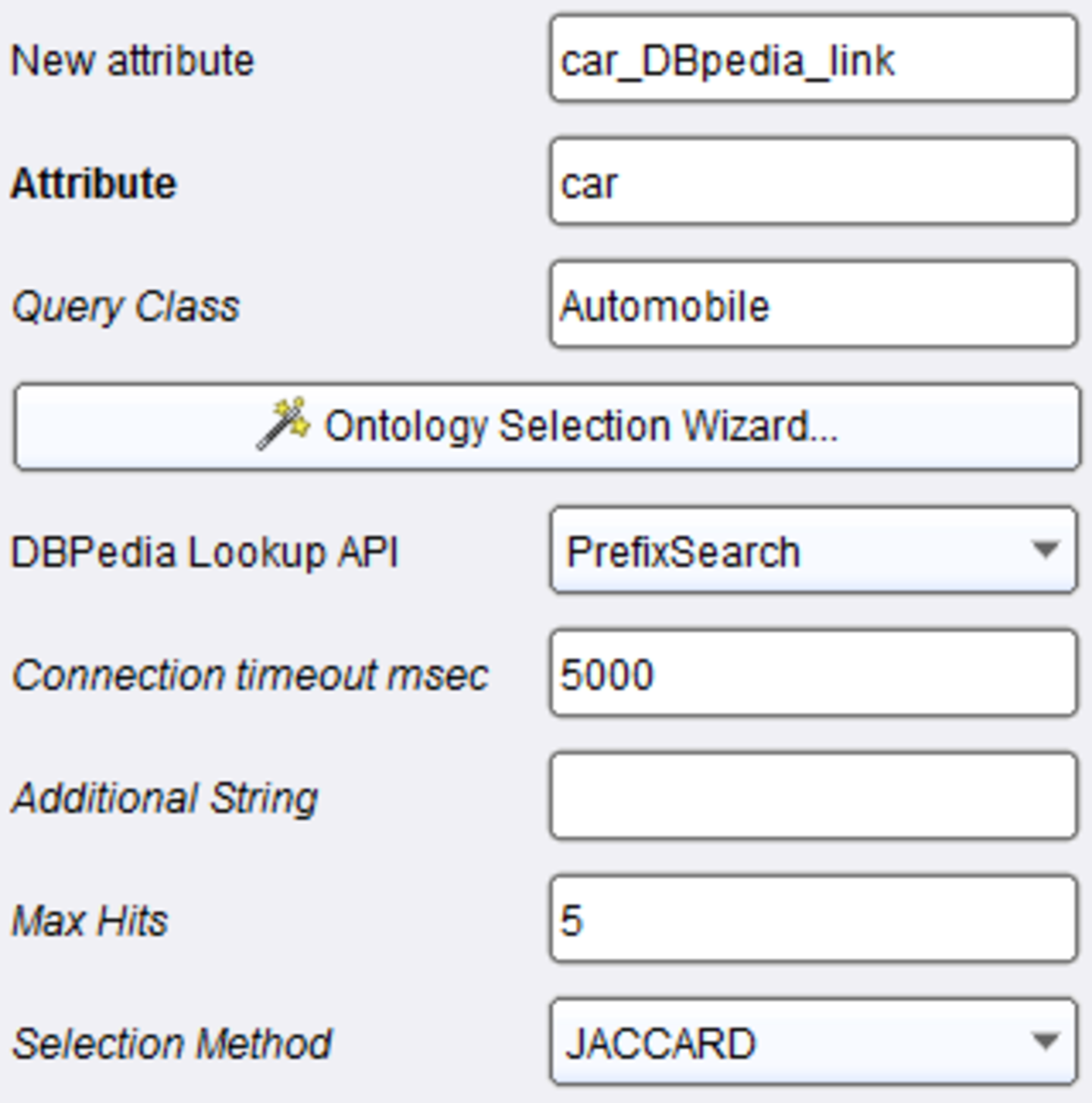
In the Specific Relation generator, we set “http://purl.org/dc/terms/subject” as the desired relation for extraction, as shown in Fig. 3. Additionally, we can extract broader categories by setting “http://www.w3.org/2004/02/skos/core#broader” in the field for hierarchy relation, and setting the desired hierarchy depth.
The output of both generators are joined in single dataset, and all attributes are converted to from nominal to numerical, using the Nominal to Numerical. Then we perform 10-fold cross validation on M5 Rules.
Results
The following table shows the results for the prediction of the fuel consumption, using only the initial plain dataset, and using the enhanced datasets. As a performance metric we are using the Relative Error. Additionally, we report the results for Linear Regression for each of the datasets.
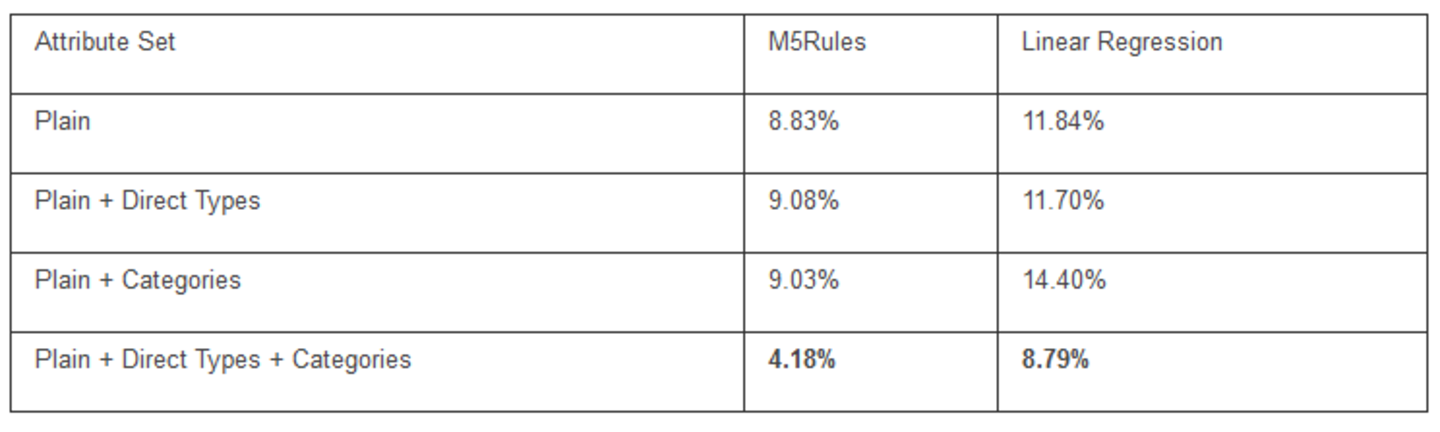
It can be observed that the best results can be achieved when combining both the attributes derived from direct types and categories.Observing the results, we can conclude that the new attributes also provide insights that are not possible from the original dataset alone. For example, the results show that UK cars have a lower consumption than others (the original origin attribute only differentiates between America, Europe, and Asia). Front-wheel-drive cars have a lower consumption than rear-wheel-drive ones (the corresponding category being positively negatively with MPG at a level of 0.411), mostly due to the fact that they are lighter. Furthermore, a correlation with the car's design can be observed (e.g., hatchbacks having a lower consumption than station wagons).