OLPBENCH – Open Link Prediction Benchmark
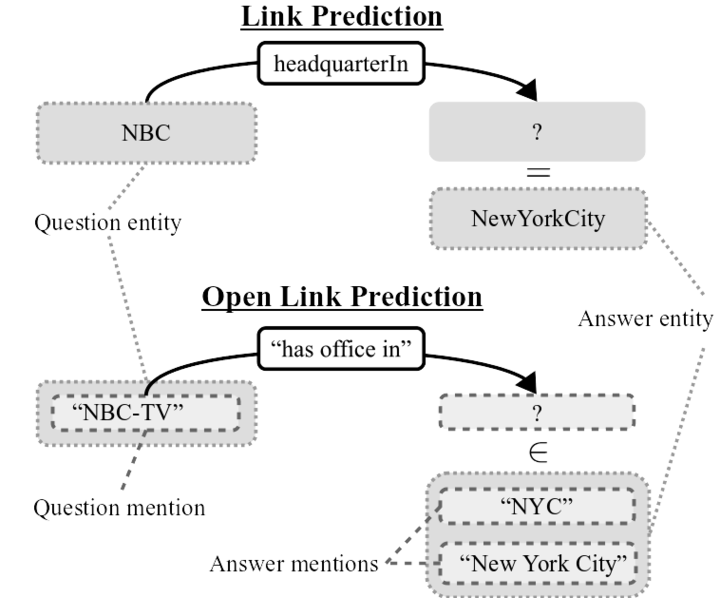
OLPBENCH is a large Open Link Prediction benchmark, which was derived from the state-of-the-art Open Information Extraction corpus OPIEC (Gashteovski et al., 2019). OLPBENCH contains 30M open triples, 1M distinct open relations and 2.5M distinct mentions of approximately 800K entities.
Open Link Prediction is defined as follows: Given an Open Knowledge Graph and a question consisting of an entity mention and an open relation, predict mentions as answers. A predicted mention is correct if it is a mention of the correct answer entity. For example, given the question (“NBC-TV”, “has office in”, ?), correct answers include “NYC” and “New York”.
Publication
Samuel Broscheit, Kiril Gashteovski, Yanjie Wang, Rainer Gemulla
Can We Predict New Facts with Open Knowledge Graph Embeddings? A Benchmark for Open Link Prediction
[ pdf ]
The 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
Data
Links for downloads regarding the OLPBENCH corpus:
- OLPBENCH: all the data (train THOROUGH, BASIC, SIMPLE, valid ALL, MENTION, LINKED and test) that was used in the paper's experiments
- Full data (compressed: ~ 2.4 GB, uncompressed: ~ 7.9 GB
- Code: code for creating OLPBENCH from OPIEC and for training the paper's models will be published on github