Mannheim Data Integration Benchmark (MaDI-Bench) released
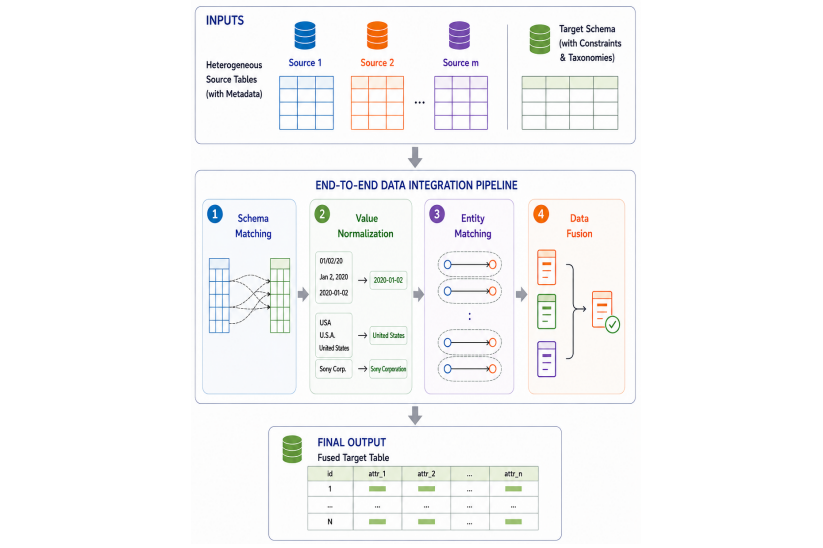
MaDI-Bench consists of five end-to-end data integration tasks: Companies, Games, Music, Products, and Scientific Papers. Each task takes several heterogeneous source tables in a domain and asks a system to return one fused target table, by performing schema matching, value normalization, entity matching, and data fusion. MaDI-Bench supports the calulation of step-wise as well as end-to-end evaluation metrics. The benchmark provides ground truth to score every step of the integration process: a gold schema mapping for schema matching, the target schema's constraints and taxonomies for value normalization, record pairs evaluating entity matchers, and hand-verified records for assessing the output of data fusion. To prevent a quick saturation of the benchmark as data integration systems progress, we introduce a generic variant-generation method for deriving harder as well as easier variants from the base tasks.
We validate the benchmark using human-engineered pipelines, a best-of-breed pipeline, and an LLM-based pipeline. The validation demonstrates the utility of the benchmark for measuring the step-wise as well as the end-to-end performance of data integration pipelines. All benchmark artefacts are available for public download.
More information about MaDI-Bench is found:
- on the project website: https://wbsg-uni-mannheim.github.io/MaDI-Bench/
- in this Arxiv paper: MaDI-Bench: An End-to-End Data Integration Benchmark
We hope that the benchmark will prove useful for the community and will support the development of fully automatic as well as human-in-the-loop end-to-end data integration systems.