Reliable Evaluation of Generative AI (ZEGeKI)
Project Vision
Generative AI like ChatGPT is ubiquitous today—both in everyday life and as a component of complex systems. In addition to ChatGPT, there are a multitude of similar AI models with varying strengths and weaknesses. A reliable performance evaluation is crucial for selecting suitable models. The established approach for this is benchmarks: static datasets consisting of question-answer pairs used to measure accuracy.
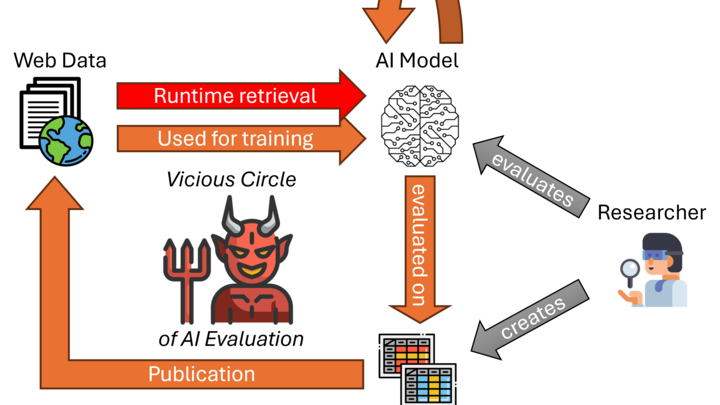
However, this approach is increasingly reaching its limits. First, targeted training on benchmarks leads to overfitting: models perform well on these benchmarks without actually possessing the abilities they are supposed to demonstrate. Second, there is a risk of benchmark leakage: Since benchmarks are publicly available, models may have already “learned” their contents—a good result is then not a true measure of competence, but rather the result of pure memorization. Third, publicly available benchmarks are hardly suitable for modern AI systems that conduct online research or engage in continuous learning.
The result: We find ourselves in a “vicious cycle of AI evaluation,” in which existing assessment and evaluation methods are increasingly losing their validity. This project breaks this cycle and pursues a radically new approach: dynamic benchmarks generated at runtime. Using the GET methodology (Generate, Evaluate, Trash), generative AI is used to continuously generate new test questions that the AI being evaluated cannot know in advance.
Funding
The project is funded by the Vector Foundation in the MINT Innovationen program with 100k euros.