
Example: Adding Background Data from Eurostat
This example shows how to enhance an existing dataset with background data from a Linked Open Data source, in this case, we use Eurostat. The corresponding RapidMiner workflow can be downloaded from myExperiment. The input CSV file is available here.
The original dataset, obtained from the OECD, is a CSV file with a list of countries and the alcohol consumption among adults. We want to enhance this file to find possible reasons for high alcohol consumption, and to build an explaining model.
We assume that the workflow has been prepared by configuring the SPARQL endpoint for Eurostat as in this example.
This picture shows the overall process in RapidMiner. Below, each step is explained in detail:
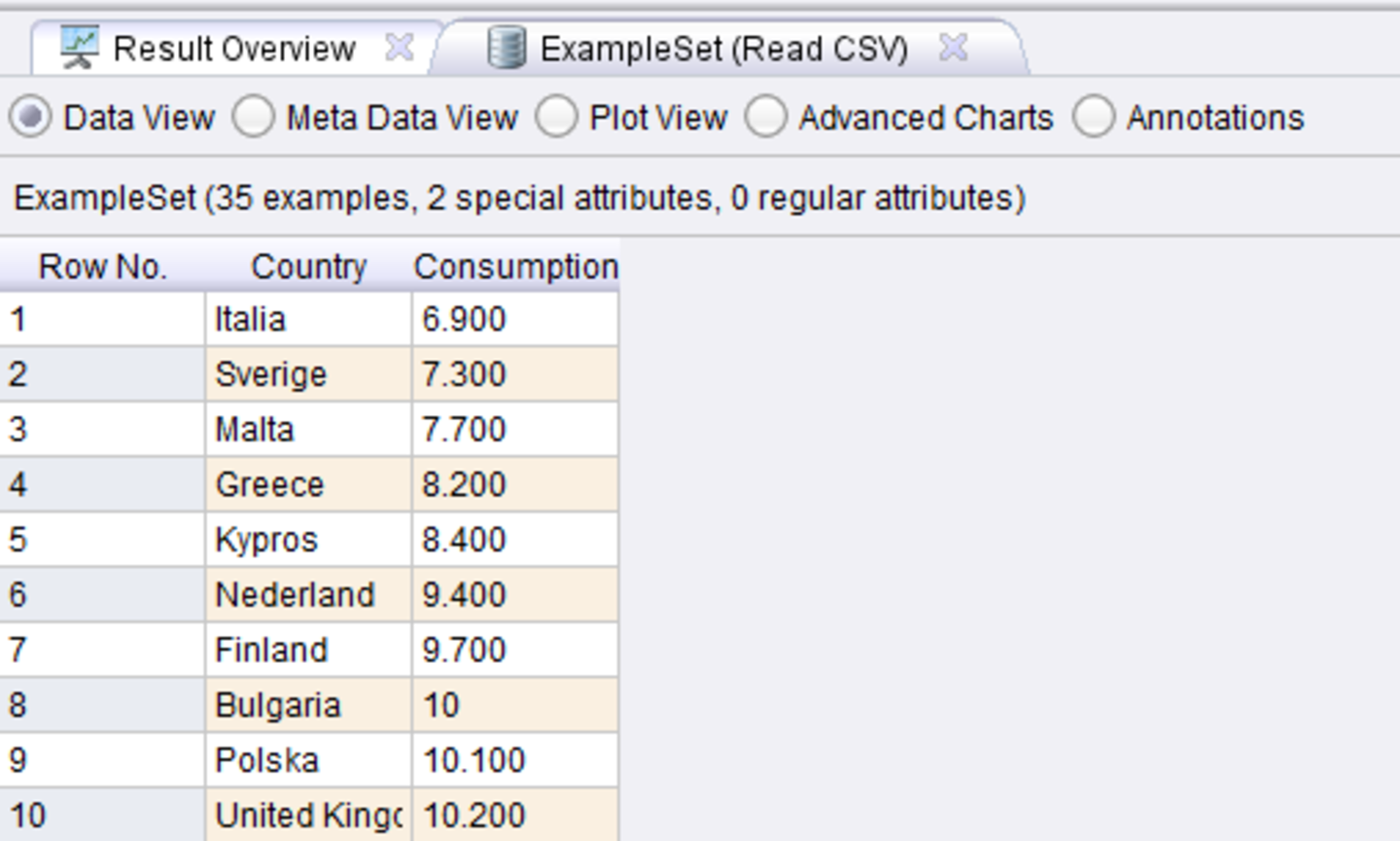
The original input data is a table containing country names and a numeric value reflecting the alcohol consumption in the country:
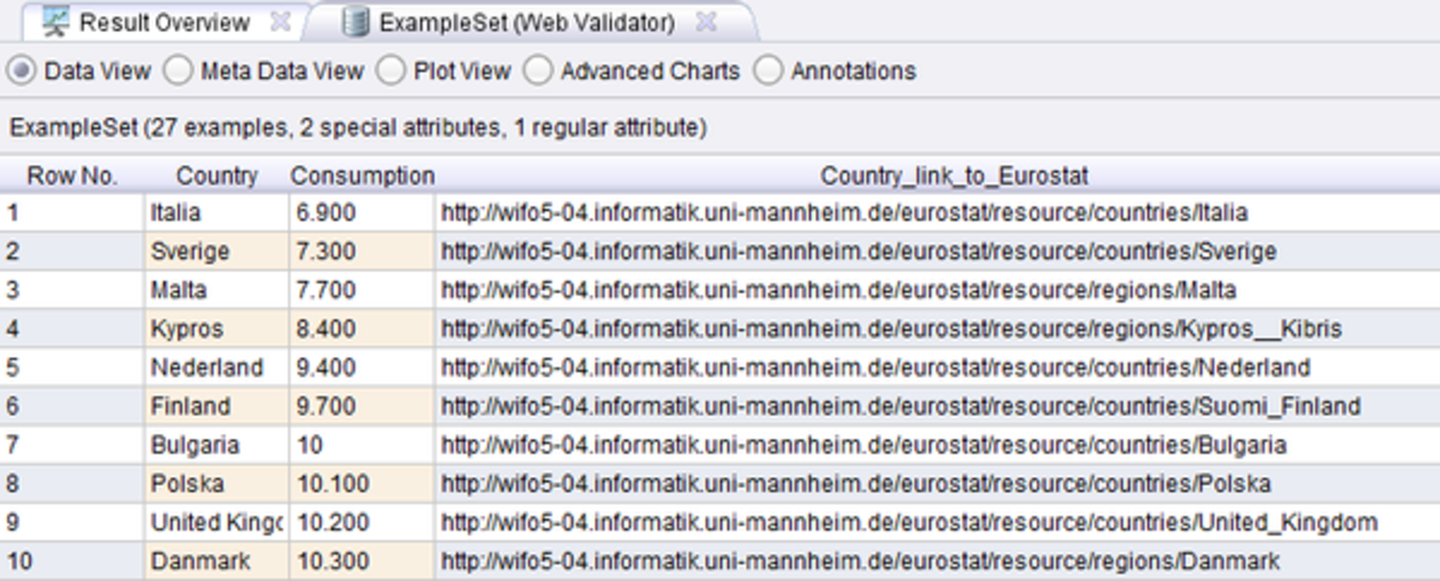
Using the Label-based linker on the Eurostat datset, the operator looks for entities that have labels identical to any of the country names. The WebValidator operator is used to remove those instances that are not found in Eurostat. The resulting table now contains a link to countries in Eurostat:
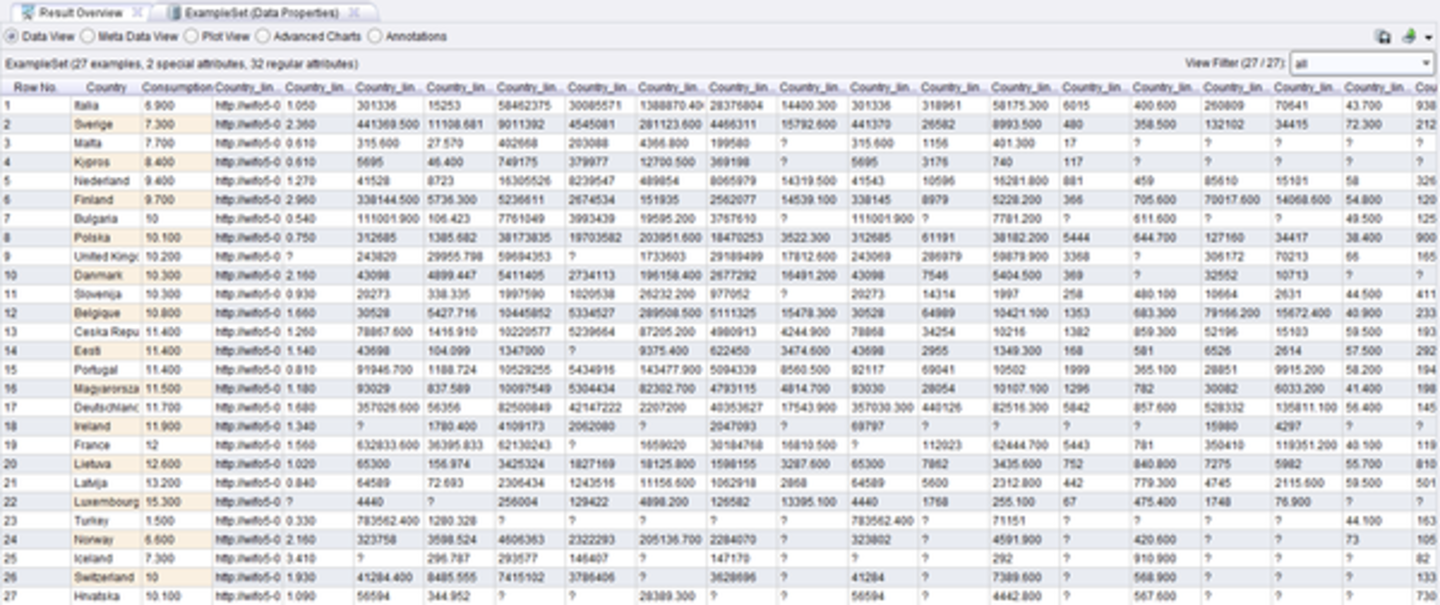
In the next step, the DataPropertyGenerator reads all data properties (e.g., GDP, population, ...) from the entities in the Eurostat dataset that have been previously identified. The result is a data table which is enhanced by many new attributes.
Finally, we want to create a model for the target variable, i.e., the alcohol consumption. To that end, we train a decision tree. As preprocessing to the decision tree learner, we first replace all missing values (as not all data properties exist for all countries, which leads to missing values in the dataset), and we discretize the data, since the decision tree learning operator cannot handle numerical data. The resulting tree looks like that:
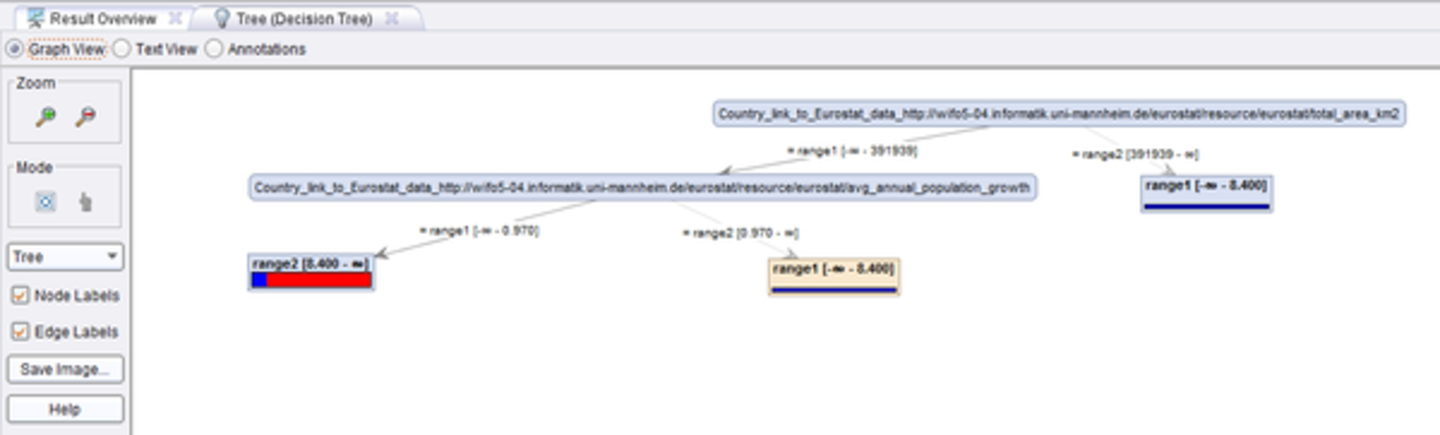
The resulting decision tree shows that alcohol consumption in smaller countries is higher than in bigger ones, and that in countries with a large population growth, the alcohol consumption is lower.
To wrap up: the RapidMiner Linked Open Data extension adds background information to a given dataset, and allows further analysis using both the original as well as the added background information.