Skip to main navigation
Skip to page content
Skip to footer
Seal of the University of Mannheim: In omnibus veritas
University Home
Intranet
University
Data and Web Science Group
News-Archiv
DWS Research
for the term
within navigation.
Full site search for
...
Home
Research
Focus Groups
Web-based Systems (Prof. Bizer)
Data Analytics (Prof. Gemulla)
Web Data Mining (Prof. Paulheim)
Natural Language Processing and Information Retrieval (Prof. Ponzetto)
Artificial Intelligence (Prof. Stuckenschmidt)
Master Thesis Topics in Artificial Intelligence
Process Analytics (Prof. Van der Aa)
Computer Vision & Machine Learning (Prof. Dr.-Ing. Margret Keuper)
Teaching CVML
People CVML
Publications
Projects
Projects
Reliable Evaluation of Generative AI (ZEGeKI)
Machine Learning
l2s
NeurIPS2025
TrackOpt
TrackOpt – ProjectPage
Learning to Sense
ClimateVisions
CosPGD
CCVision Network Meeting
Context Matters
Current Projects
Completed Projects
Resources
People
Professors
Prof. Dr. Christian Bizer
Prof. Dr. Rainer Gemulla
Prof. Dr.-Ing. Margret Keuper
Prof. Dr. Heiko Paulheim
Prof. Dr. Simone Paolo Ponzetto
Prof. Dr. Heiner Stuckenschmidt
Prof. Dr. Philipp Kellmeyer
Dr. Sven Hertling
Prof. Dr. Daniel Schuster
Advanced Process Mining
Dr. Ralph Peeters
Researchers
Postdoctoral Research Fellows
Andreea Iana
Steffen Jung
Dr. Juan Cano de Benito
Daniel Ruffinelli
Dr. Ines Rehbein
Dr. Christian Meilicke
Rita Torres de Sousa
PhD Students
Kerstin Beckersjürgen
Julia Gastinger
Tejaswini Medi
Aaron Steiner
Daniel Kerger
Shashank
Katharina Prasse
Mishal Fatima
Keyvan Amiri Elyasi
Darshit Pandya
Alexander Bubak
Patrick Betz
Lea Cohausz
Jakob Kappenberger
Christopher Klamm
Julie Naegelen
Keti Korini
Franz Krause
Alexander Kraus
Ricarda Link
Ines Reinig
Sotaro Takeshita
Simon Forbat
Affiliated PhD Students
Patrick Müller
Administration
Alumni
Yuxuan Zhou
Alexander Brinkmann
Dr. Federico Nanni
Dr. Melisachew Wudage Chekol
Dr. Ioana Hulpus
Samuel Broscheit
Dr. Chia-Chien Hung
Dr. Robert Litschko
Adrian Rebmann
Dr. Michael Schlechtinger
Fabian David Schmidt
Dr. Adrian Kochsiek
Dr. Nicolas Heist
Prof. Dr. Paul Swoboda
Dr. Pedro Ortiz Suarez
Dr. Sarah Alturki
Dr. Jovita Lukasik
Dr. Amirhossein Kardoost
Kiril Gashteovski
Prof. Dr. Goran Glavaš
Dr. Anna Primpeli
Dr. Anne Lauscher
Dr. Taha Alhersh
Dr. Jakob Huber
Dr. Jonathan Kobbe
Dr. Timo Sztyler
Dr. Dmitry Ustalov
Dr. Oliver Lehmberg
Dr. Yaser Oulabi
Alexander Diete
Dr. Kilian Theil
Career
Teaching
Large Computations
Lecture Videos
Thesis Guidelines
Course Details
Courses for Master Candidates
IE 500 Data Mining
IE 560 Foundations of Artificial Intelligence – Reasoning and Decision Making
DS 203: Responsible AI
IE 650 Knowledge Graphs
IE 661 Text Analytics
IE 663 Information Retrieval and Web Search
IE 670 Web Data Integration
IE 671 Web Mining
IE 675b Machine Learning
IE 678 Deep Learning
IE 685 Large Language Models and Agents
IE 695 Reinforcement Learning
IE 696 Advanced Methods in Text Analytics
Advanced Process Mining (APM)
IE 694 Industrial Applications of Artificial Intelligence
CS 717: Seminar on Explainable AI Methods
CS 560 Large-Scale Data Management
CS 460 Databases for Data Scientists
CS 646 Higher Level Computer Vision
CS 668 Generative Computer vision Models
CS 647 Image Processing
CS 704 Artificial Intelligence Seminar
CS 704 Social Simulation Seminar
CS 704 Traffic Forecasting with Neural Networks Seminar
SM445/
CS 707: Seminar “Machine Learning on Structured Data” (FSS2026)
CS 709 Text Analytics Seminar
SM451/
CS710 Seminar on Benchmarking AI
CS 715: Seminar on Solving Complex Tasks using Large Language Models
CS 717: Seminar on Computer Vision
SM 459: Seminar on Computer Vision
CS 718 AI and Data Science in Fiction and Society
CS 719 Process Analysis Seminar
Data Analytics Team Project – Your Project, Your Team
Colloquium
Team Projects
CS 717: Seminar on Causality and Neurosymbolic Learning
Course Archive
FSS 2026
HWS 2025
SM445/
CS 707: Seminar “Machine Learning at Scale” (HWS 2025)
Data Analytics Team Project – Your Project, Your Team
SM 445/
CS 707 Data and Web Science Seminar
Courses for Bachelor Candidates
CS717: Seminar on Explainable AI Methods
Wirtschaftsinformatik IV: Datengetriebene Analytics
CS 303 Praktische Informatik II
SM 445 Data and Web Science Seminar
SM 451 Seminar Ethical AI
Wirtschaftsinformatik II/
IV
Künstliche Intelligenz
Wirtschaftsinformatik für Wirtschaftspädagogen und BaKuWis
Wirtschaftsinformatik für BaKuWis
KI Seminar
Course Archive
FSS 2025
HWS 2024
FSS 2024
HWS 2023
FSS 2023
HWS 2022
FSS 2022
HWS 2021
FSS 2021
HWS 2020
FSS 2020
HWS 2019
FSS 2019
HWS 2018
FSS 2018
HWS 2017
Courses for PhD Candidates
Colloquium FSS2023
Computational Text Analysis
+
Search
Barrierefreiheit
EN
Menu
University
Data and Web Science Group
News-Archiv
DWS Research
DWS Research
1
2
3
4
5
6
7
…
next
New Project on Reliable Evaluation of Generative AI
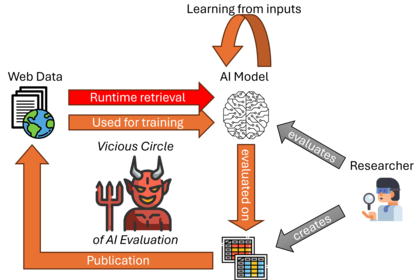
The Vector Foundation funds the project ZEGeKI (Zuverlässige Evaluation Generativer KI, English: Reliable Evaluation of Generative AI). The motivation of this project lies in the observation that, following open science principles, benchmarks for evaluating AI systems (not limited to, but ...
CCVisions 2026 in Mannheim
We are hosting 4th annual CCVision Network Meeting June 23, 2026 Organized by: Katharina Prasse, Anastasia Kanat , Prof. Dr.-Ing. Margret Keuper
2 Papers Accepted for BPM 2026
We are happy to announce that the following papers have been accepted for BPM 2026 in Toronto, Canada Lukas Kirchdorfer, Artemis Doumeni, Han van der Aa and Hugo A. López: From Global Policies to Local Strategies: Multi-Objective Optimization of Resource-Specific Handover PoliciesKeyvan Amiri ...
Two Papers Accepted at ESWC 2026
Two papers have been accepted at the European Semantic Web Conference 2026.
Two Papers accepted at ICLR 2026
We have two papers accepted at ICLR 2026!
Paper on Agent Interfaces to the Web accepted at the Web Conference 2026
We are happy to announce that the paper “MCP vs RAG vs NLWeb vs HTML: A Comparison of the Effectiveness and Efficiency of Different Agent Interfaces to the Web” by Aaron Steiner, Ralph Peeters, and Christian Bizer been accepted for the the ACM Web Conference 2026 as a short paper. The Web conference ...
Paper on Multi-Task Learning Accepted for the International Journal of Computer Vision
We are happy to announce that the paper “Investigating Uncertainty Weighting for Multi-Task Learning: Insights and Analytical Alternatives” by Lukas Kirchdorfer, Tobias Sesterhenn, Christian Bartelt, Heiner Stuckenschmidt, Lukas Schott and Jan M. Köhlerhas been accepted for the International Journal ...
Paper accepted at ACM TORS
The paper “Multilinguality in MIND: Advancing Cross-lingual News Recommendation with a Multilingual Dataset” by Andreea Iana, Goran Glavaš, and Heiko Paulheim has been accepted in ACM Transactions on Recommender Systems (TORS). Abstract: Digital news platforms rely on recommendation systems to ...
Paper accepted at BMVC 2025
Our paper 3D-WAG: Hierarchical Wavelet-Guided Autoregressive Generation for High-Fidelity 3D Shapes, T. Medi, A. Rampini, P. Reddy, P.K. Jayaraman, M. Keuper has been accepted at BMVC 2025! Congrats to all co-authors!
Paper accepted at TPAMI
Our paper Examining the Impact of Optical Aberrations to Image Classification and Object Detection Models has been accepted at TPAMI ! Congratulations to all co-authors!
1
2
3
4
5
6
7
…
next
In order to improve performance and enhance the user experience for the visitors to our website, we use cookies and store anonymous usage data. For more information please read our
privacy policy
.
Allow
Reject
Tracking cookies are currently allowed.
Do not allow tracking cookies
Tracking cookies are currently not allowed.
Allow tracking cookies