
Robust Decision Tree Induction from Unreliable Data Sources
Credit: Christian Schreckenberger
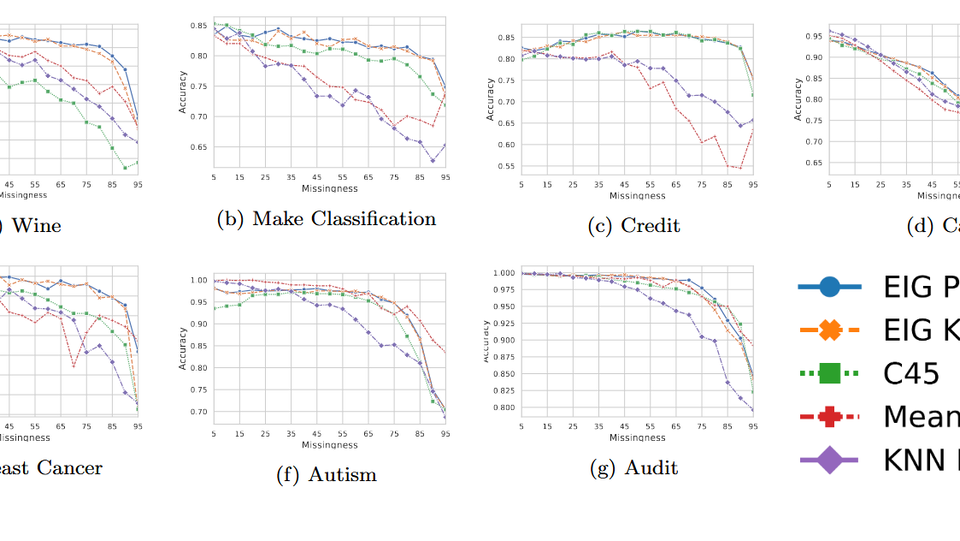
Expected Information Gain can be used to build more robust decision trees given the circumstance of missing data. We evaluate the criterion on six UCI datasets and one synthetic dataset in three scenarios: No missing data at prediction time, missing data at prediction time, and imputed data at prediction time. The results of the proposed methods are promising in all scenarios. However, especially in the second scenario the potential of learning a more robust model with the proposed method becomes apparent.